What 1,400 B2B SaaS Sales Calls Reveal About Discovery and Demo

A guest analysis by Nils Brosch, B2B SaaS sales trainer (Benelux & DACH)
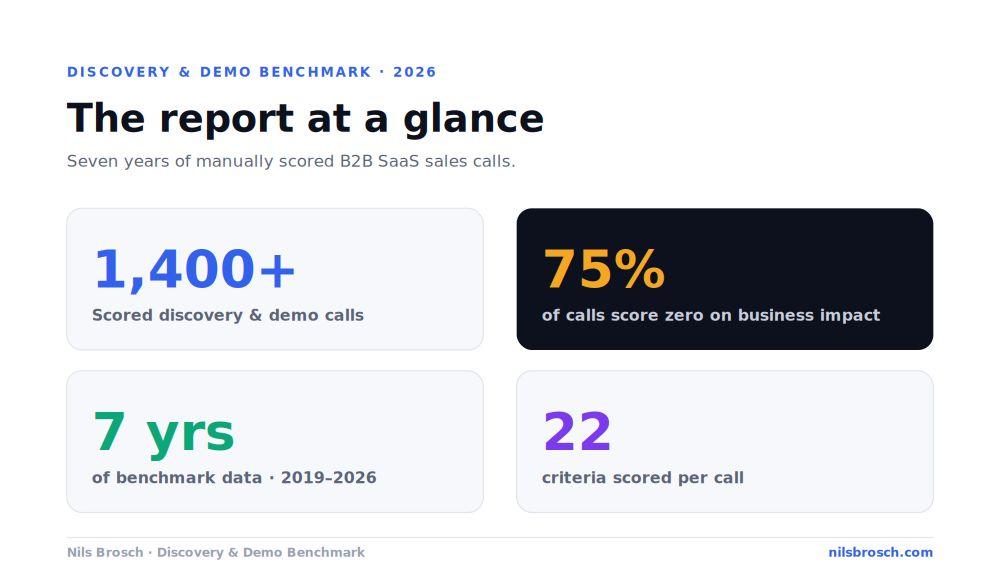
TL;DR
I have manually scored more than 1,400 discovery and demo calls across European B2B SaaS teams over seven years, against the same 22-criterion rubric every time. The pattern is consistent and uncomfortable. Reps are good at the parts of a call that feel like conversation, and bad at the parts that require commercial discipline. 75% of calls score zero on business impact. Only 23% of reps reach impact at all, only 26% try to shift the buyer's vision, and fewer than 10% do both. The demo does not rescue the deal. It inherits the discovery problem and makes it visible. This is not a training-content gap. It is a knowledge and management gap, and it is fixable.
Neil Rackham published SPIN Selling in 1988. That is nearly four decades of the sales world agreeing on one thing: the quality of your discovery determines the quality of your pipeline. Every major methodology since, from MEDDIC to Command of the Message, is a variation on that theme. You have almost certainly trained your team on some version of it.
So here is the question that bothered me enough to build a dataset around it. If everyone agrees discovery matters, why do so few teams actually do it well?
To answer that, I did something most sales benchmarks skip. I did not run a survey. I did not ask reps to self-report. I sat down and scored the actual recordings. Over seven years (2019 to 2026), across multiple European B2B SaaS teams, I assessed more than 1,400 discovery and demo calls against a fixed rubric of 22 criteria, each scored yes, somewhat, or no. Every individual data point is anonymised. What follows is what the calls actually contain, not what anyone thinks they contain.
This is the part of the 2026 Discovery & Demo Benchmark I find most worth talking about: the gap between the methodology everyone owns and the behaviour almost no one executes.
The 75% problem: reps find the pain, then stop
Here is the single number that should stop a sales leader scrolling.
75% of B2B SaaS discovery calls score zero on business impact. Not partial. Not weak. Zero.
Business impact, in my rubric, means the rep establishes what the problem actually costs the buyer in real terms. Wasted hours, lost candidates, leaked revenue, the price of doing nothing for another quarter. It is the difference between "yes, that's annoying" and "that's costing us roughly €40k a quarter." Across the dataset, business impact averages 0.23 on a 0-to-1 scale, the lowest-scoring discovery criterion of all.
Reps are not lazy. They find the pain. Pain exploration is one of the stronger discovery criteria in the data. What they do not do is quantify it. They hear a problem, nod, validate it, and move on to the next question on their mental checklist.
Think of a doctor who listens carefully to your symptoms, agrees they sound unpleasant, and then never tells you what happens if you leave them untreated. You would not feel any urgency to book the surgery. You would go home and see if it clears up on its own. That is exactly what a buyer does after a discovery call with no impact: nothing.
Without impact, there is no cost of inaction. Without a cost of inaction, there is no urgency. Without urgency, there is no business case. You are not qualifying a deal at that point. You are hoping one forms on its own.
One-dimensional discovery: why your reps sound like every other vendor
The impact gap is a symptom of a deeper habit I call one-dimensional discovery.
One-dimensional discovery is the act of extracting information the buyer already has. Two-dimensional discovery adds something the buyer did not walk in with: a new consequence, a pattern from a similar company, a question they were not expecting.
One-dimensional discovery feels productive. The rep asks good questions, the buyer answers, the notes fill up. But every single thing learned is something the buyer already knew about their own situation. And here is the problem with that: every other vendor in the deal is collecting the exact same information. You all walk away with the same notes, which means the buyer evaluates all of you against the same requirements they had before any of you showed up.
You have made yourself comparable. And comparable means competing on price.
The data shows how rare the alternative is. Watch what happens as you move from one skill to the next:
- 23% of reps reach genuine impact discovery
- 26% attempt to shape or change the buyer's vision (scored as the "User Story / New Information" criterion, averaging just 26)
- Fewer than 10% do both in the same call
That last number is the whole game. Fewer than one in ten reps both quantify the cost of the problem and introduce a new lens on it. If your team is in that 10%, you are not competing on the same axis as everyone else. You set the axis.
Here is what two-dimensional discovery sounds like in practice, taken from a real pattern in the data. A rep selling recruitment software is talking to a healthcare company. The one-dimensional version asks, "Why is hiring speed a priority right now?" and lets the buyer explain. The two-dimensional version asks the same opening question, listens, and then adds: "A similar healthcare group told us their bigger bottleneck was actually how candidates dropped off between application and first contact, because nurses apply on their phone and never check email. Does that resonate?" And the buyer says, "Actually, yes. We hadn't thought about it that way."
Same product. Same prospect. Completely different deal. New insight creates a new requirement. A new requirement creates a new comparison. And now there is a problem in the buyer's mind that only you surfaced.
The criteria nobody coaches
When you rank all 22 criteria from strongest to weakest, a clean pattern appears. It is not random which skills score well.
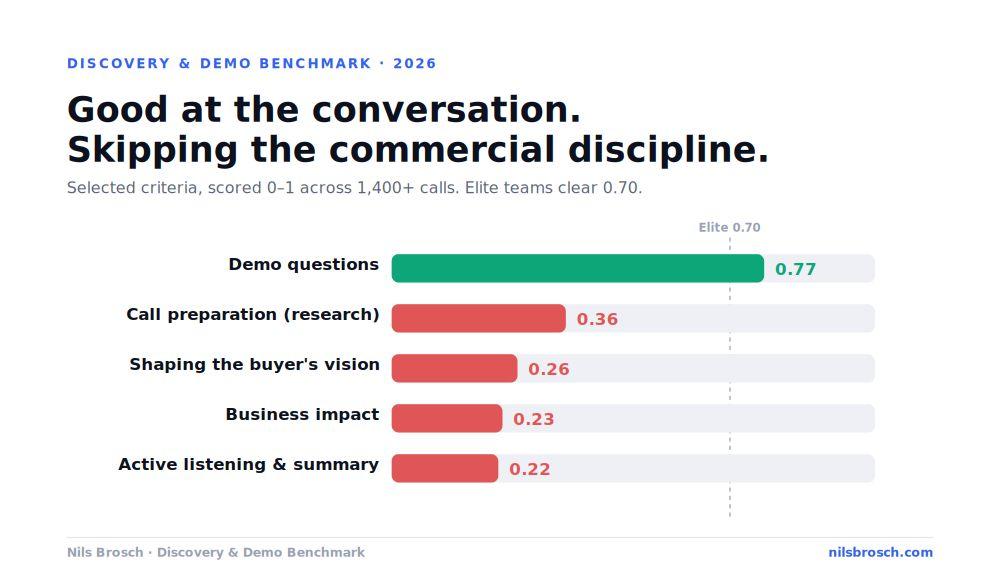
Reps reliably do the things that feel like a conversation. They open warmly. They build situational understanding. In the demo, they ask discovery questions throughout (demo questions score 0.77, the highest criterion in the entire dataset).
Reps reliably fail at the things that require commercial discipline and active interpretation. Business impact (0.23). Active listening and summary (0.22). Shaping the buyer's vision (0.26). Future-state exploration. These are the criteria where the rep has to do something with the information rather than just collect it.
The skills that score lowest are not the hard-to-learn ones. They are the hard-to-observe ones.
That distinction matters because it explains why the gap persists despite years of training. A manager reviewing a pipeline can see whether a deal exists. They cannot see, from a forecast spreadsheet, whether the rep ever quantified impact on the call. The lowest-scoring criteria are precisely the ones that are invisible unless someone listens to the recording. So they go uncoached, year after year.
It also explains why pre-call research scores so poorly. Across the dataset, call preparation comes in at 36%, meaning fewer than one in three reps do genuine research before the call. That single habit feeds nearly everything downstream: a warmer opening, sharper situational understanding, better pain exploration, a real read on the competitive landscape. Most reps treat research as a box to tick. The data says it is the foundation the rest of discovery is built on.
The demo does not fix it. It compounds it.
A common assumption is that a weak discovery can be saved by a strong demo. The data says the opposite. The demo inherits the discovery problem and puts it on full display.
The demo phase averages 0.51 overall, but the spread tells the story:
Demo criterion | Score (0-1) | What it means |
Demo questions | 0.77 | Reps keep asking throughout. Good. |
Demo agenda | 0.55 | Roughly half set up the demo properly. |
Pain-led prioritisation | 0.50 | Half tailor what they show to the pain. |
Discovery-to-demo alignment | 0.39 | Most demos are not anchored to discovery. |
Anchoring | 0.36 | Few connect features back to cost or value. |
Customer stories | 0.10 | Stories are almost never used. |
Demo phase criteria, ranked. Customer stories at 0.10 is the lowest score across both phases of the call.
Customer stories at 0.10 is staggering. The single most persuasive tool a rep has, the proof that someone like the buyer solved this exact problem, shows up in roughly one demo in ten.
But the deeper point is structural. The demo weaknesses mirror the discovery weaknesses exactly. A rep who never reached impact in discovery has nothing to anchor the demo to. So the demo becomes a feature walkthrough, because the discovery never generated the ammunition for a pain-led presentation. The demo is not a separate skill problem. It is the discovery problem, downstream.
The hybrid call trap
There is one finding I want to single out, because it is the most actionable thing in the entire benchmark and almost nobody talks about it.
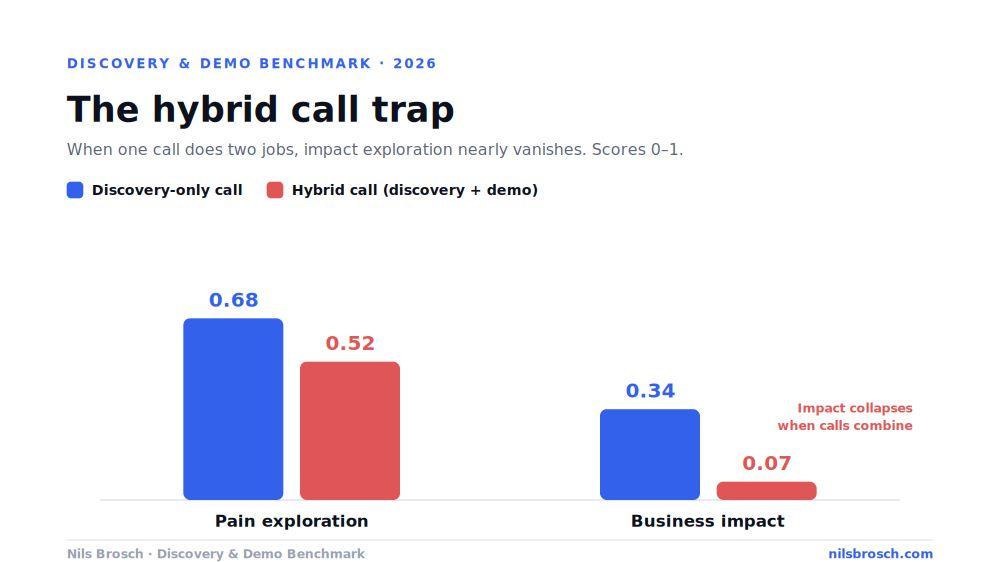
When I segmented the calls by type, something jumped out. I split 206 classifiable calls into discovery-only, demo-only, and hybrid (a single call doing both jobs at once). Here is how impact and pain held up:
Criterion | Discovery-only | Hybrid |
Pain exploration | 0.68 | 0.52 |
Business impact | 0.34 | 0.07 |
Tool demo | n/a | 0.61 |
Discovery quality collapses when a single call has to do two jobs. Impact exploration nearly vanishes.
Look at impact. In dedicated discovery calls it scores 0.34. In hybrid calls it collapses to 0.07. When reps try to cram discovery and demo into one conversation, impact exploration almost completely disappears. There is a fascinating wrinkle on the other side: the demo itself actually lands better in hybrid calls (0.61 versus 0.35 for standalone demos), because it sits on top of fresh context. But the price is that the diagnosis that makes the whole deal worth pursuing gets skipped.
The hybrid call is where deals quietly die. The demo looks great. The qualification never happened.
So long-story-short: if your reps are running combined discovery-and-demo calls to save the prospect's time, you are very likely trading away the single most important thing a discovery call produces.
What this means if you are a rep
Most of this benchmark is a message to sales leaders. But if you carry a bag, here is what the data says will separate you from 90% of the people you are competing against. None of it is complicated.
- Do the research. Fewer than one in three of your competitors will. Twenty minutes on LinkedIn and the company's recent news changes your opening from "tell me about your business" to "I noticed you expanded into Germany, I came with specific questions about that."
- Quantify the pain. When you find a problem, do not move on. Ask the second question: what does that cost you? In hours, in money, in deals lost, in risk. If you cannot put a rough number on the problem, you have not finished discovery.
- Bring one new thing. Before you pitch, introduce something the buyer did not have. A pattern from a similar company, a consequence they had not considered. Change the buying vision and you change the comparison.
- Use a story in the demo. One in ten reps does. Find the customer who looked like this buyer, and tell that story before you click into the feature.
- Protect your discovery. If you can avoid collapsing discovery and demo into one call, do. And if you cannot, force yourself to ask the impact question anyway, because that is the first thing that disappears under time pressure.
Why this is a management problem, not a rep problem
It would be easy to read all of this as "reps are bad at their jobs." I do not believe that, and the data does not support it. The criteria reps fail at are not the difficult ones. They are the unobservable ones. They persist because the management layer reviews pipeline, not process. A manager knows a deal is stuck. They rarely know why it is stuck at the conversation level, because no one has a shared, precise language for what good looks like at each stage of a call.
That is the real finding underneath the headline numbers, and it is where I am taking this work next. My next benchmark focuses on sales management itself: what the best sales managers in B2B SaaS actually do differently, measured the same way, from the ground up. If the discovery benchmark told us what reps do on calls, the management benchmark asks why those behaviours never get corrected.
Frequently asked questions
What is a good discovery call benchmark score in B2B SaaS?
Across 1,400+ scored calls, the discovery phase averages around 0.49 on a 0-to-1 scale. Elite teams average above 0.70. The fastest way to beat the benchmark is to improve the three lowest criteria: business impact (0.23), active listening and summary (0.22), and shaping the buyer's vision (0.26).
Why do most discovery calls fail?
The most common failure is not a lack of questions. It is one-dimensional discovery: reps extract information the buyer already has, but never quantify the cost of the problem or introduce a new perspective. In the data, 75% of calls score zero on business impact, which removes the urgency and business case the rest of the deal depends on.
Should reps combine discovery and demo into one call?
The data suggests caution. In hybrid calls, impact exploration collapses from 0.34 to 0.07. The demo can actually land better on fresh context, but the diagnostic work that qualifies the deal almost always gets skipped. If you must combine them, deliberately protect time for the impact question.
How was the benchmark built?
By manually scoring more than 1,400 real discovery and demo calls across European B2B SaaS teams over seven years (2019 to 2026), against a fixed rubric of 22 criteria, each scored yes, somewhat, or no. It is observed behaviour, not survey data, and all individual data is anonymised.
Where to go from here
If you want to see exactly where your team sits against this data, the full 2026 Discovery & Demo Benchmark Report is free to download, with the complete ranking of all 22 criteria and the tier breakdown. You will find it, along with the rest of my work on B2B SaaS discovery, demo, and sales coaching, on the site of Nils Brosch, B2B SaaS sales trainer.
And if the management angle is the one that resonated, that is the benchmark I am releasing next. Follow me on LinkedIn to get the B2B SaaS sales management benchmark when it drops.
One thing to try this week: pull one recorded call from your best rep and one from a struggling rep, and listen only for the impact question. You will learn more in those two calls than in a quarter of pipeline reviews.



